

🌪️ AI is changing the internet AGAIN
Catch the 'privacy & AI' train before it's too late


👋 Hi, Luiza Jarovsky here. Happy New Year! Welcome to the 84th edition of the newsletter. Thank you to 80,000+ followers on various platforms and to the paid subscribers who support my work. To read more about me, find me on social, or drop me a line: visit my personal page. For speaking engagements, fill out this form.
✍️ This newsletter is fully written by a human (me), and I use AI to create the illustrations. I hope you enjoy reading as much as I enjoy writing it!
🙏 With gratitude

Before I start, I would like to thank YOU, dear reader. I write this newsletter to share analyses, reflections, and resources in privacy, tech & AI, and it's always great to receive your warm messages and enthusiastic feedback. I hope I can keep the standards high and continue improving in 2024. I sincerely wish you a year full of health, love, joy, and growth.
And a special thanks to all our newsletter sponsors in the last year: MineOS, Didomi, Osano, Ubiscore, Neutronian, Conformally, Tom Kemp, Piiano, Guardsquare, Incogni, and the Center for Financial Inclusion - thank you for the trust and support. It's exciting to grow together!
➡️ To become a sponsor and reach thousands of privacy & AI decision-makers in 2024: get in touch (only 3 spots left for Q2).
🌪️ AI is changing the internet AGAIN
The year has barely started, and the New York Times vs. OpenAI lawsuit signs massive AI-led changes to the internet as we know it. Here's what's happening:
AI applications based on large language models (LLMs) need huge amounts of data to be developed, and so far, most of the data has been extracted for free from the internet (scrapping).
To get free data, AI companies rely on two main arguments:
a) that their unlicensed use of copyrighted content (such as NYT articles) to train their AI models represents a new “transformative” purpose and thus "fair use";
b) that their collection and processing of personal data from social networks and other platforms where users post content is a form of "legitimate interest" (EU) or legal unless it's against a website's Terms of Use (US);
-
On item "a," the New York Times, in its lawsuit against OpenAI, brought clear arguments against fair use. A quote from the lawsuit:
"Because the outputs of Defendants’ GenAI models compete with and closely mimic the inputs used to train them, copying Times works for that purpose is not fair use." (page 4)
After reading the lawsuit, I doubt OpenAI will manage to avoid the NYT's copyright fees. Hopefully, these fees will help compensate the people behind high-quality journalism, and this is good.
-
On item "b" above, from an EU perspective, according to the GDPR, legitimate interest has its own requisites. Besides complying with a 3-part test, controllers have to follow data protection principles such as transparency and its specific rules.
According to Article 14 of the GDPR, data subjects (all of us) should be warned when their data is being processed by third parties and receive details about the entities processing the data.
Have any of you been warned about OpenAI and other companies using your social media posts to train AI systems? I wasn't.
For now, my take is that most companies developing LLMs have not complied with GDPR requirements to process data lawfully, and this processing (and any product built with this data) is illegal, at least in the EU.
To change that, as I've been advocating, they must be proactively transparent about their practices, and personal data should be taken seriously.
Back to item "b" above, from a US perspective, websites are building code-based and Terms of Service-based barriers against scrapping. With these new walls, the only way to get access to the data would be through individual agreements with the platforms.
My opinion is that these individual agreements are a positive development, as they will end up forcing the platforms to notify people when there are AI companies using the content to train AI models (and people can decide if they continue posting or not).
There is so much going on, and even more to come. The year has barely started, but it's already time to run to catch the ‘privacy & AI’ train before it's too late.
*If you want to dive deeper into Privacy & AI, consider our 4-week Bootcamp starting on January 31. Learn more and register here.
🔵 On legitimate interest and AI training
For some, this is an unpopular opinion, but the GDPR also applies when creating and training AI datasets - and many tech companies are ignoring it. This must change:
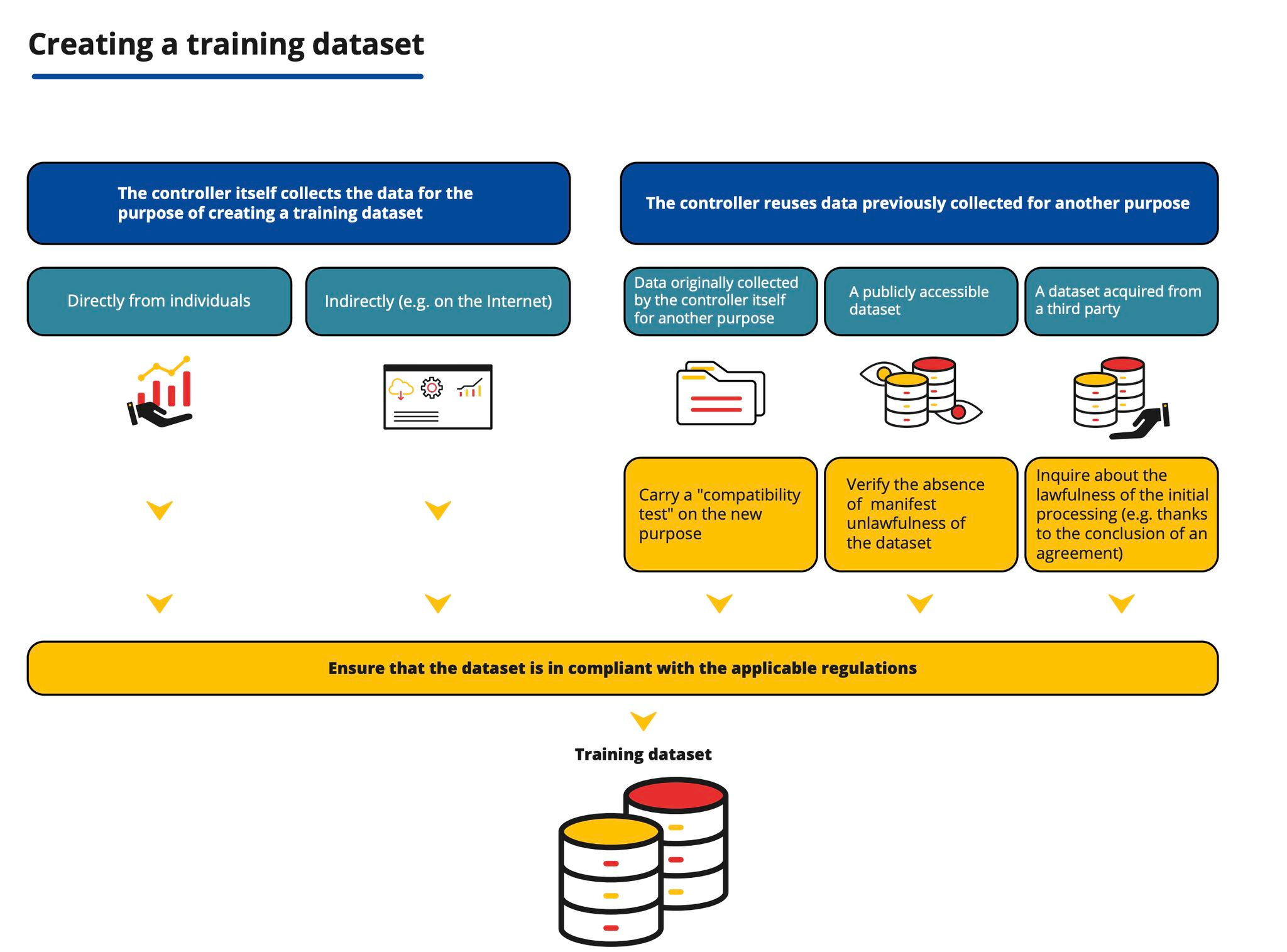
As the CNIL's (the French Data Protection Authority) infographic above shows, regardless of the data source, data protection law must be observed when creating a training dataset.
A reminder that Article 6 of the GDPR establishes that these are the possible ways to process personal data lawfully:
- consent
- contract
- legal obligation
- vital interest
- public interest
- legitimate interested
Most AI companies developing large language models today rely on legitimate interest to scrape data from the web and train their models.
However, despite seeming an "easy" alternative, legitimate interest has its own legal requisites, including the three-part test (purpose, necessity, balancing), transparency, data minimization, and storage limitation.
Regarding the three-part test, according to the ICO (Information Commissioner's Office), it can be summarized as follows:
“Purpose test: are you pursuing a legitimate interest?
Necessity test: is the processing necessary for that purpose?
Balancing test: do the individual’s interests override the legitimate interest?"
In this context, a few weeks ago, OpenAI updated its EU privacy policy. However, they deal with AI training issues in a separate link, which you can find at their Help Center: “How ChatGPT and Our Language Models Are Developed.”
On this page, they present the following paragraph, where they argue that they have a legitimate interest in processing personal data to train their AI models:
“We use training information lawfully. Large language models have many applications that provide significant benefits and are already helping people create content, improve customer service, develop software, customize education, support scientific research, and much more. These benefits cannot be realized without a large amount of information to teach the models. In addition, our use of training information is not meant to negatively impact individuals, and the primary sources of this training information are already publicly available. For these reasons, we base our collection and use of personal information that is included in training information on legitimate interests (…)”
The idea that tech companies can rely on legitimate interest to train AI systems through scraping to feed generative AI applications is not obvious. This is a new interpretation/legal construct of the legitimate interest reasoning that deserves further analysis.
A reminder that Recital 47 of the GDPR says that:
“legitimate interest could exist for example where there is a relevant and appropriate relationship between the data subject and the controller in situations such as where the data subject is a client or in the service of the controller.”
“the existence of a legitimate interest would need careful assessment including whether a data subject can reasonably expect at the time and in the context of the collection of the personal data that processing for that purpose may take place.
“The interests and fundamental rights of the data subject could in particular override the interest of the data controller where personal data are processed in circumstances where data subjects do not reasonably expect further processing.”
Recital 47 also offers a few examples of the applicability of legitimate interest, including the prevention of fraud and direct marketing.
Questions/issues:
When our data is being used to train AI models, we do not have a direct relationship with the controller (the tech company training the AI system);
When we are using a social network, for example, we do not expect that our data is being used to train an external AI system;
We are not notified that our data is being used to train AI systems;
We might oppose this type of data processing for privacy reasons.
Next week, I would like to dive deeper into the legitimate interest issues, showing that basic GDPR principles have been forgotten.
With the quick and ubiquitous integration of generative AI and large language models-based capabilities into daily applications, data protection law must be implemented and made effective (or privacy rights and advancements - which took so much effort and time to become legally enforceable - will be undermined).
I cover the topic of AI training privacy compliance (among many others) on our 4-week Bootcamp on privacy & AI, starting on January 31st. Learn more and register register here.
Privacy matters, also when AI is involved. This will be a hot topic in 2024, and regulators, advocates, researchers, and privacy professionals will have to get involved.
💛 Enjoying the newsletter? Share it with friends and help us spread the word. Let's reimagine technology together.
📝 Warming up for 2024
To help you warm up for 2024, I invite you to take a look at our top 10 most popular newsletter editions from 2023 (every edition is read by thousands of people all over the world).
They give you a glimpse into what is trending and what to expect for 2024. Make sure to read, bookmark, and check again when relevant:
Visit also our archive and the list of our most popular newsletter editions of all time.
🎤 Upcoming live talk

*Coming up next week, register here (free).
On Tuesday, January 8, I will discuss with three leading privacy experts, Odia Kagan (Fox Rothschild), Nia Cross Castelly (Checks / Google), and Gal Ringel (MineOS), what to expect and how to get ready for emerging privacy challenges. We'll talk about:
the hottest privacy topics for 2024 and why they will be important/impactful;
what will be the most challenging privacy issues for business and why;
how businesses can prepare in advance for these challenges and the most important practical measures organizations and professionals should be thinking about right now;
tips for privacy professionals who want to navigate 2024 successfully.
This is a free event, and if you are a privacy professional, you cannot miss it! Register here to be notified when it starts, participate live, comment in the chat, and receive the recording to re-watch.
🏢 Job opportunities

Our privacy job board is one of the most popular privacy careers pages on the internet, and our AI job board is growing at high speed. If you are looking for a job or know someone who is, share these links with them. If you would like to include your organization's job openings, get in touch.
📚 AI Book Club

Our recently launched AI Book Club already has 450+ members, and we are now reading “The Coming Wave: Technology, Power, and the Twenty-first Century's Greatest Dilemma” by Mustafa Suleyman. Are you an avid reader? Would you like to join a critical discussion about AI? Register and join our next meeting.
🦋 4-week Privacy, Tech & AI Bootcamp

To dive deeper into privacy & AI, join our 4-week Bootcamp starting on January 31. It includes 4 live sessions with me (one hour per week), additional reading material (~ 1 hour per week), quizzes, 8 CPE credits pre-approved by the IAPP, and a course certificate. There are limited seats: see the full program and register here for the January cohort.
🎓 Privacy managers: schedule a training

600+ professionals from leading companies have attended our interactive training programs. Each of them is 90 minutes long (delivered in one or two sessions), led by me, and includes additional reading material, 1.5 CPE credits pre-approved by the IAPP, and a certificate. To book a private training program: contact us.
🔥 Have you heard of data maximization?
Have you heard of the right to automated decision-making (human-out-of-the-loop) and the right to complete and connected datasets (data maximization)?
In September, I spoke with Prof. Orly Lobel, author of various books, including the acclaimed "The Equality Machine," in which she argues that "while we cannot stop technological development, we can direct its course according to our most fundamental values."
In our one-hour conversation, we spoke about various topics, including some of the ideas she discusses in her book and her article "The Law of AI for Good," such as her argument that:
"the right to human decision-making (human-in-the-loop) and the right to privacy (data minimization) - must be complemented with new corollary rights and duties: a right to automated decision-making (human-out-of-the-loop) and a right to complete and connected datasets (data maximization)."
She gives various examples of how AI can help improve fairness and defends the idea that we should focus on harnessing the power of technology - including AI - to help protect fundamental rights (instead of being a priori against automation and AI-related advancement).
She is one of the pioneers in this line of thought, and the discussion is extremely important in the context of the upcoming AI Act (hopefully soon) and various AI legislations around the world.
Watch our 1-hour conversation on my YouTube Channel or listen to it on my podcast.
This is the type of critical and necessary conversation I'll be holding this year - stay tuned!
Before you go: what have you been reading recently? I would love to know - reply to this email and let me know.
Happy New Year!
Luiza