

🥊 OpenAI's GPT Store vs. Data Protection
Plus: Generative AI, copyright, and creativity


👋 Hi, Luiza Jarovsky here. Welcome to the 87th edition of this weekly newsletter. Thank you to 80,000+ followers on various platforms and to the paid subscribers who support my work. To read more about me, find me on social, or drop me a line: visit my personal page. For speaking engagements, fill out this form.
✍️ This newsletter is fully written by a human (me), and I use AI to create the illustrations. I hope you enjoy reading it as much as I enjoy writing!
A special thanks to SciSpace, this edition's sponsor:
In a world with long literature reviews and complex jargon among many scientific hindrances, SciSpace’s AI-powered platform empowers academics to turbocharge their research. With SciSpace, you can discover 282M+ scientific papers effortlessly, analyze and contrast everything on one screen, and also get real-time assistance from Copilot. Get unlimited access to SciSpace at 40% off on the annual plan - use coupon code LUIZA40. For a monthly plan, get 20% off with LUIZA20. Start today
➡️ To become a newsletter sponsor and reach thousands of privacy & tech decision-makers: get in touch (booked until May).
🥊 OpenAI's GPT Store vs. Data Protection
The GPT store and other “model-as-a-service” commercialization platforms might pose a significant data protection challenge; here's why:
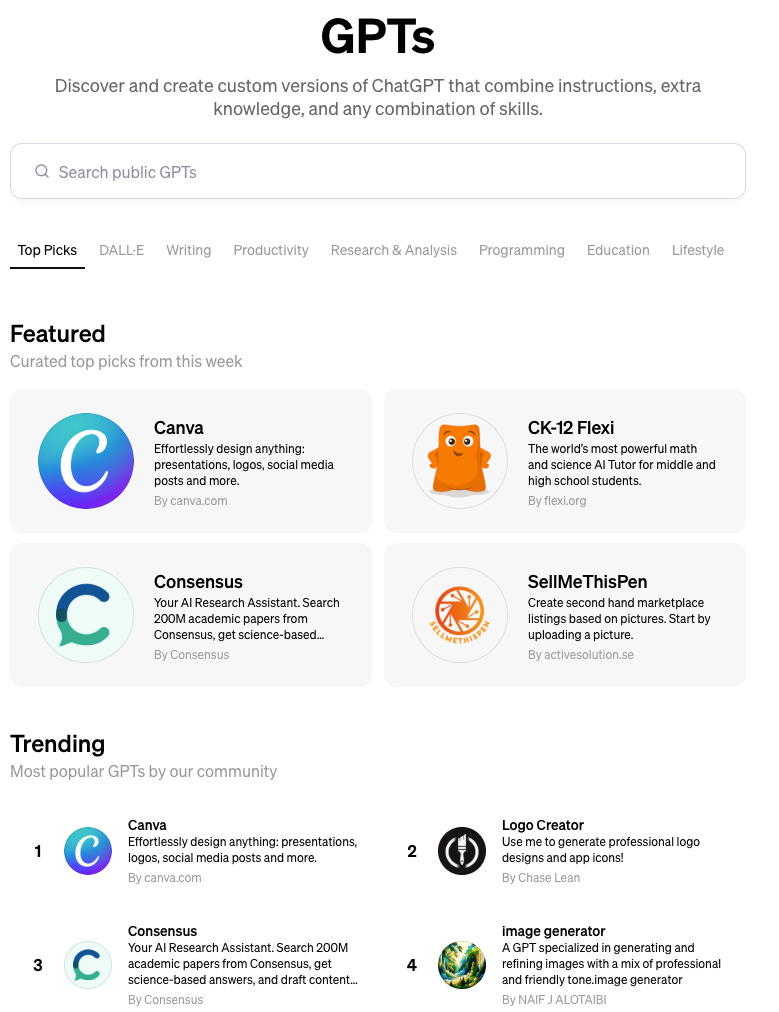
The GPT Store
A few days ago, OpenAI launched the GPT Store, where developers can offer their custom versions of ChatGPT. They wrote on their blog:
"Today, we're starting to roll out the GPT Store to ChatGPT Plus, Team and Enterprise users so you can find useful and popular GPTs."
Here is a screenshot of the GPT Store:
The FTC on “model-as-a-service” companies
One day before the GPT Store went live, the FTC published a blog post entitled "AI Companies: Uphold Your Privacy and Confidentiality Commitments."
In this post, the FTC talks about “model-as-a-service” companies, which are companies that "develop and host models to make available to third parties via an end-user interface or an application programming interface (API)."
This definition can apply to OpenAI when they act as suppliers of AI APIs to third-party developers. It also applies to various other companies, such as Amazon, Google, and Microsoft, offering similar services.
Regarding these companies and their commitment to privacy and confidentiality, the FTC declared:
"Model-as-a-service companies that fail to abide by their privacy commitments to their users and customers, may be liable under the laws enforced by the FTC. This includes promises made by companies that they won’t use customer data for secret purposes, such as to train or update their models—be it directly or through workarounds. In its prior enforcement actions, the FTC has required businesses that unlawfully obtain consumer data to delete any products—including models and algorithms developed in whole or in part using that unlawfully obtained data. The FTC will continue to ensure that firms are not reaping business benefits from violating the law."
[On a side note, I am always positively surprised by the FTC's promptness. For those who hold the old belief that the law is always behind technological development: think again. Especially in the privacy field and in the context of regulatory systems like the American one (where the FTC can quickly deploy its enforcement powers), this is not true, and the regulator is always watching - even before launch.]
The GPT Store's data protection challenge
The GPT Store - especially in the context of a platform allowing “model-as-a-service” transactions - poses a fundamental data protection challenge, which might require us to rethink AI development and commercialization.
Legitimate interest
As I've commented in this newsletter in recent weeks, OpenAI has declared on its website that it relies on legitimate interest (GDPR - Art 6) to process data to train their AI systems. It's on a page called "How ChatGPT and Our Language Models Are Developed," separate from their privacy policy.
To me, this is still an open question, as it's unclear if they can convincingly pass the three-part test (to prove legitimate interest) or if they can comply with other data protection principles (such as transparency) in the course of their processing activities to sustain this position.
In any case, their legitimate interest claims are based on how ChatGPT uses data. By launching the GPT Store, they now have a new data protection challenge.
Why?
The GPT Store works in a format that the FTC has coined "model-as-a-service," in which third-party companies will rely on OpenAI's large language model (LLM) to develop their own GPTs through the API.
These third-party developers work independently and will not necessarily comply with legitimate interest requirements.
And why is it relevant to OpenAI?
If these third-party developers who are relying on OpenAI's API do not comply with legitimate interest requirements, then OpenAI's lawfulness in processing data during the training phase is potentially undermined.
Solutions?
A possible solution to this could be strong usage rules that attempt to make sure that legitimate interest requirements are maintained by all GPTs being offered at the GPT Store.
But it's challenging. For example, the GPT Store has “usage policies,” and one of the rules states: "(...) GPTs that contain profanity in their names or that depict or promote graphic violence are not allowed in our Store. We also don’t allow GPTs dedicated to fostering romantic companionship or performing regulated activities."
While this seems a good rule, a few days ago, Business Insider reported that "OpenAI's GPT Store is being flooded by AI girlfriend bots despite explicit rules that prohibit them."
As I've discussed in this newsletter a few times, AI companions are problematic from a data protection perspective; it would be difficult to claim that there is legitimate interest in training an AI model for this purpose.
Moreover, third-party AI developers can also build AI applications whose features, capabilities, and policies, despite not being illegal or clearly against usage rules, would undermine OpenAI's legitimate interest claim. Would a GPT that classifies women as being “hot or not” according to certain beauty standards comply with legitimate interest? I can think of many examples of GPTs that would not necessarily go against current laws or usage policies, but that might undermine legitimate interest claims.
I'm all for AI development and growth, but I think it should happen while respecting laws, ethics, transparency, and fairness. Now it's the right time to make it happen!
-
*I will discuss this topic in our 4-week Privacy, Tech & AI Bootcamp. I invite you to check out the program, and if you think it might help you advance your career, register here (if you are a student or NGO employee, contact us and request a discount).
💸 Pay or consent
The current state of cookie banners: “excited to share your personal data with 800 third parties? No? So pay €1 now!” Here's a recent screenshot from a Spanish newspaper:
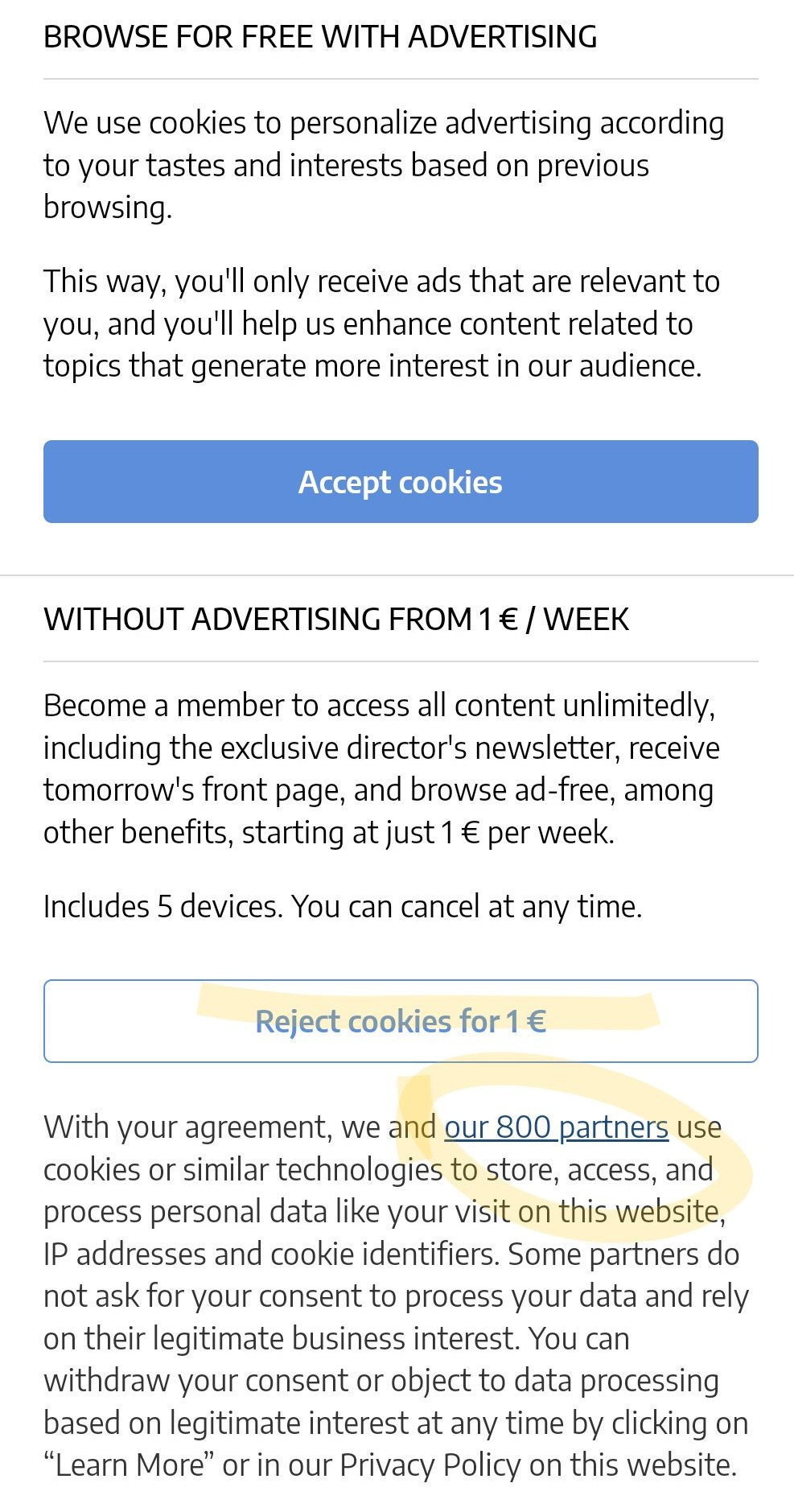
In line with Meta's switch to “subscription for no ads” - and noyb's subsequent lawsuit, I see more and more newspapers having cookie banners similar to the one above.
The good part is that the EU seems to be revisiting the concept of cookie banners, so hopefully, more favorable models will emerge. According to Techspot:
“European Union Justice Commissioner Didier Reynders recently told German newspaper 'Welt am Sonntag' that the European Commission is aware of how annoying cookie consent banners have become and is discussing a remedy. He said that although websites can no longer activate cookies without informing users about them, the stipulation shouldn't turn web browsing into a tiring affair”
After writing about the topic extensively in my Ph.D. research, and although I am an advocate of the importance of user autonomy, I'm not convinced anymore of how much autonomy can a cookie banner convey in practice. Maybe it's time to try something different.
⚖️ Generative AI vs. copyright
My unpopular opinion on the topic is that it's time to reimagine copyright law and compensation rules.

According to the Salon article above, OpenAI said in its evidence filing to a House of Lords subcommittee in the UK
"It would be impossible to train today's leading AI models without using copyrighted materials ... Limiting training data to public domain books and drawings created more than a century ago might yield an interesting experiment, but would not provide AI systems that meet the needs of today's citizens."
My questions on that:
- Why do individuals (and not companies) have to bear the creative cost of "leading AI models"?
- Why not propose other forms of compensating artists, authors, and creators?
- Why not consider fair compensation during AI training an inherent part of the AI business model?
The technological wave moves fast, and it's up to us humans to make it work according to human values and interests.
✍️ What is human creativity?
The widespread adoption of generative AI tools - including writing books like this Telegraph article reported - will force us to answer a few important questions:

- Does it matter if an author or artist uses AI?
- Do we want to value the same way a book or any creative expression developed with the help of AI?
- Should there be rules to protect "NO AI" human work (let's say, similar to "food without pesticides")?
- Should authors and artists be obliged to disclaim in any context that they were supported by AI?
- Etc
The future of creative expression - including the incentive for 'authentically human' creative work - is at stake. We must also question ourselves what 'authentically human' work means.
Interesting times.
💛 Enjoying the newsletter? Share it with friends and help me spread the word. If you want to access the full newsletter and support my work, consider a monthly or yearly subscription. Thank you!
🎤 Tackling Dark Patterns & Online Manipulation in 2024
If you work in privacy, tech, design, or marketing, you can't miss our upcoming live talk. Here's why:

I invited two globally acknowledged scholars - Prof. Cristiana Santos and Prof. Woodrow Hartzog - to discuss with me their perspectives on dark patterns (deceptive design), design regulation, and how industry and policymaking professionals can avoid online manipulation and help build a better internet. We'll talk about:
- The past, present, and future of dark patterns
- Laws against dark patterns and the challenges of regulating design
- Dark patterns in code
- The challenges of identifying, documenting, and curbing online manipulation
- Deepfakes, anthropomorphism, and other forms of AI-related manipulation (which I call dark patterns in AI)
*Register here so that you will: receive a notification when the session is about to start; be able to join us online and comment in the chat; and receive a recording of the session in your email to watch & re-watch later.
A special thanks to MineOS, the sponsor of this live talk & podcast episode.
I hope to see you there on February 6!
➡️ To become a sponsor of our live talks & podcast episodes and reach thousands of privacy & tech decision-makers: get in touch.
🚨 New paper on generative AI, privacy & more

The paper "Generative AI in EU Law: Liability, Privacy, Intellectual Property, and Cybersecurity" was published a few days ago by Claudio Novelli, Federico Casolari, Philipp Hacker, Giorgio Spedicato, and Luciano Floridi, and it covers some of my favorites emerging privacy & AI topics, which I've been discussing in this newsletter (check the archive). I highlight two of them below:
a) Legitimate interest
"Hence, for legal and economic reasons, AI training can typically be based only on the balancing test of Article 6(1)(f) GDPR (Zuiderveen Borgesius et al. 2018; Zarsky 2017), according to which the legitimate interests of the controller (i.e., the developing entity) justify processing unless they are overridden by the rights and freedoms of the data subjects (i.e., the persons whose data are used)." (page 10)
This has been the lawfulness argument used by companies such as OpenAI to train their AI models. I've been questioning if, in practice, they can pass legitimate interest's three-part test and if they can comply with other data protection principles that support this line of argument/justification.
Above, in this newsletter, I also questioned the applicability of the legitimate interest argument in the context of complex AI models such as the "model-as-a-service" format deployed at the GPT Store by OpenAI.
b) Transparency
"When considering data harvested from the internet for training purposes, the applicability of Article 14 of the GDPR is crucial. This article addresses the need for transparency in instances where personal data is not directly collected from the individuals concerned. However, the feasibility of individually informing those whose data form part of the training set is often impractical due to the extensive effort required, potentially exempting it under Article 14(5)(b) of the GDPR. Factors such as the volume of data subjects, the data's age, and implemented safeguards are significant in this assessment, as noted in Recital 62 of the GDPR. The Article 29 Working Party particularly notes the impracticality when data is aggregated from numerous individuals, especially when contact details are unavailable (Article 29 Data Protection Working Party 2018, para. 63, example)." (page 12)
On this topic, I've been arguing in favor of clearer and more straightforward transparency notices in consumer-facing interfaces (regardless if there is AI involved), possibly aligned with the concept highlighted by Prof. Ryan Calo a few years ago called "visceral notices."
Specifically in the AI context, I've proposed that platforms that host user content being harvested for AI training should be responsible for conveying this information to users and allowing them to opt-out.
This is a very interesting paper, raising important legal discussions in the context of generative AI.
🤖 Jobs in privacy & AI

If you are looking for a job or know someone who is, we have a privacy job board and an AI job board containing hundreds of open positions
In addition to that, every week, we send a weekly alert with selected job openings in privacy & AI governance; visit the links above and subscribe or share it with your friends. Good luck!
📚 AI Book Club: Unmasking AI
Interested in AI? Love reading and would like to read more? Our AI Book Club is for you! There are already 600+ people registered. Here's how it works:

We are currently reading “Unmasking AI,” written by Dr. Joy Buolamwini, and we'll meet on March 14 at 2pm ET to discuss it. Five book commentators will share their perspectives, and everybody is welcome to join the 1-hour discussion.
- Interested in participating? Register using this form, invite friends, and start reading!
- Reading the book and want to be one of the 5 book commentators? Write to me.
Happy reading!
🦋 Privacy, Tech & AI Bootcamp: Get 8 CPE credits

Because the first cohort sold out fast, there are 2 additional cohorts of our Privacy, Tech & AI Bootcamp starting in February! A reminder that the Bootcamp lasts 4 weeks and grants you 8 CPE credits pre-approved by the IAPP.
Read the full program and register here. There are special coupons for students, NGO members, and people who cannot afford the fee: if this is your case, contact us.
🎓 Privacy managers: upskill your team

600+ professionals from leading companies have attended our training programs. Each of them is 90 minutes long (delivered in one or two sessions), led by me, and includes additional reading material, 1.5 CPE credits pre-approved by the IAPP, and a certificate. Click the image above to learn more and book a private training for your team.
🎬 Privacy: What to Expect in 2024
It's Data Privacy Week, and you can't miss the recording of this month's episode with three privacy rockstars - Odia Kagan (Fox Rothschild), Nia Cross Castelly (Checks/Google), and Gal Ringel (MineOS) - on privacy challenges in 2024. You can find the recording of our conversation on my YouTube channel or podcast.
Wishing you a great week!
All the best,
Luiza