



🌐 The AI-powered internet: legal issues
AI policy & regulation | Luiza's Newsletter #103


👋 Hi, Luiza Jarovsky here. Welcome to the 103rd edition of this newsletter on AI policy & regulation, read by 23,900+ subscribers in 130+ countries. I hope you enjoy reading it as much as I enjoy writing it.
➡️ A special thanks to Usercentrics for sponsoring this week's free edition of the newsletter. Check out their article:

We all know that data privacy regulations require user consent. But what’s critical now is establishing how your business will use it to grow sustainably. Make your customers happy and crank up your revenue engine. Get practical inspiration with Usercentrics' article on consent-based marketing. What it is and isn’t, how to do it well, and specific steps to solidify your strategy and evolving operations. Learn more here.
🌐 The AI-powered internet: legal issues
The AI-powered internet is here, and not many people have realized it yet. Below is a summary of what's happening and some of the legal implications:
➡️ Social networks, news websites, media repositories, and every website we usually visit to consume or post content are becoming AI-Training-As-A-Service platforms. Through content licensing deals, the user content is transferred to AI companies (such as OpenAI) to train their AI models. Companies like Meta, which have the user data AND the AI models, are editing the Privacy Policy and the Terms of Service to state that all user data is fair game for them to train their AI systems.
➡️ The remaining websites, including major e-commerce and gaming platforms, are heavily incorporating AI functionalities and tools and incentivizing users to create or edit content using AI.
➡️ Given the ongoing cycle of data input, output, and recycling for AI training and the ubiquitous "create with AI" functionalities, it looks like soon, most of the information available online will be synthetic.
➡️ This is the beginning of the transition from an ad-based internet into something else. This something else will be AI-powered, synthetic, fast-paced, personalized, biased, and with less human autonomy.
➡️ Why less human autonomy? In the AI-powered internet, supporting autonomy is inefficient, as the AI-powered chatbot or agent can quickly output a single answer based on the whole internet (instead of providing a list of links, as in a search engine).
➡️ The AI-generated output will be designed to please the user based on what the model already knows about the user and their biases.
➡️ The model will also reflect its developers' biases, as they will be the decision-makers regarding which content should be allowed and which should not and what the model objectives, rules, and guardrails are.
➡️ "Truth" and "facts" will become outdated concepts, as everything will be digested by immense AI models, synthesized, and personalized back to the user. There will be no place for consensus or universal truths. If you thought there were "bubbles" in the ad-supported internet, this will not even be an issue in the new internet, as each one will have their own personalized AI-powered web.
➡️ Given the ongoing changes caused by the ubiquity of AI-generated content and AI-powered tools and functionalities, some of the legal frameworks that used to work in the pre-generative AI era will be ineffective.
➡️ I'd go as far as to say that soon most legal fields will need some sort of update or reinterpretation to fit the post-AI disruption reality.
➡️ There is also the legislative and policymaking boom around AI, and many new laws and official recommendations have been proposed in a short period of time. The EU AI Act is an example, and there are various other bills being discussed around the world.
➡️ More legal disruption is coming (overall, a positive one, which also generates jobs and opportunities for legal professionals). Legal professionals should keep their eyes open, as what they knew from a few years ago might soon not be valid anymore.
➡️ In terms of practical legal effects, besides the already existing AI-related challenges affecting data protection, consumer, administrative, and intellectual property law, I see big clashes in constitutional law, especially regarding free speech issues, which will be modulated through tech platforms and AI systems' specifications.
➡️ It will be difficult (if not impossible) to scrutinize and control every "free speech-related" micro decision by the AI model, especially when these decisions happen billions of times every day in a personalized manner. As a result, AI systems (and their developers) will largely control how and what we can read, say, or think.
➡️ I'm an optimistic person, and I think we'll find creative ways to overcome the ongoing and upcoming challenges. The earlier we notice these issues, the better.
➡️ If you are interested in learning more about the legal implications of AI-related disruption, check out our training programs and register for the June cohorts (limited seats).
🇪🇺 OpenAI's GPT-4o and the EU AI Act
OpenAI has just made a demo showing the new capabilities of GPT-4o ("o" stands for "omni"), and here's a legal issue most people didn't notice:

➡️ At one point, an OpenAI employee asks the AI system to detect his emotion (see the screenshot above). A reminder that according to the EU AI Act - Article 5.1 (f) - the following AI practice is prohibited:
"the placing on the market, the putting into service for this specific purpose, or the use of AI systems to infer emotions of a natural person in the areas of workplace and education institutions, except where the use of the AI system is intended to be put in place or into the market for medical or safety reasons"
➡️ OpenAI will have to ensure that AI-based emotion recognition is not deployed in workplaces or education institutions that are subject to the EU AI Act.
➡️ The new capabilities are certainly impressive, and as it's not all about hype, the legal challenges to make them compliant are only starting.
📑 Recommended AI Paper
➡️ The paper "AI and Epistemic Risk for Democracy: A Coming Crisis of Public Knowledge?" by John Wihbey is a must-read for everyone interested in AI ethics. Quotes:
"In some ways, the very structure of artificial intelligence technologies, namely the building of predictive models based on past data (backward-looking training data), is fundamentally in conflict with basic aspects of democratic life, which is inherently forward-looking. Democracy is fundamentally emergent; AI models are epistemically anachronistic. (...) AI models will always carry a kind of epistemic risk, as they are structurally missing vast amounts of data about what humans actually consider to be true, important, useful, and interesting." (page 12)
"The obvious solution is to keep humans in the loop, allowing the AI news agent to continue to get human signals and provide access to values and preferences that are not that of the machine. Yet that will require a very deliberate effort to wall off a zone of human cognitive resources that are not themselves the byproducts of AI shaping. It will also require some strong normative preference for ideas, values, preferences, and interactions that directly derive from humans, and are not mediated by AI." (page 17)
"Setting aside the ability of chatbots to perform the job reasonably well – the functionality problems that remain formidable – there is a larger question about the potential loss of social and knowledge value for democracy as machines begin assuming the tasks of refereeing public conversations over issues in the digital public square. What would be lost? The answer, potentially, is public knowledge – about what people think, how they argue, the norms they battle for, and the preferences that they reveal as they debate and deliberate." (page 20)
"Achieving ethical alignment for AI technologies and engaging in smart mechanism design will require technical innovation and careful training of models. However, such technical work is necessary but not sufficient. Some degree of epistemic modesty must be factored/programmed into the design of AI models as they bear on democratic life and deliberation. There must be space to create and preserve human cognitive resources that are not substantially shaped by AI-mediating technologies. If not, the era of AI threatens to become a giant exercise of recursion for democracies." (page 26)
➡️ Read the full paper here.
📌 Resources on AI, tech & privacy
If you enjoy this newsletter, you might also want to subscribe to our:
➵ Job alerts: receive a weekly curation of privacy & AI governance jobs
➵ AI Book Club: receive our AI book recommendations
➵ Learning Center: receive information on upcoming learning opportunities in AI, tech & privacy
🗂️ Google Gemini: where does the data come from?
What are Gemini's - Google's AI model - training data sources? Why are tech companies allowed to hide this information?
➡️ After digging into Google's various Terms of Service and Privacy Policies, this is what I found:
"We process information from publicly accessible sources and your Gemini Apps information so that we can provide, maintain, improve, and develop Google products, services, and machine learning technologies."
➡️ Questions:
➵ What publicly accessible sources?
➵ What is Google's approach to "publicly accessible"?
➵ What is included and what is excluded?
➵ What are special precautions taken to protect personally identifiable information?
➡️ How is it possible that one of the largest and most valuable tech companies in the world does not have additional information to share about how they train their massive AI systems?
➡️ How can we properly scrutinize tech companies and their AI systems if they get away with very low transparency standards?
➡️ For those that did not realize, from a legal perspective, tech companies' trick has been the following:
➵ They focus on how they use user input data (the data users input while interacting with the AI system), sometimes allowing users to use the system anonymously, telling users not to input confidential information, and so on;
➵ They make sure to hide the details about the training dataset, including the data sources and the detailed composition of the data used to train their AI systems.
➡️ Remember OpenAI's Mira Murati's interview in which she could not specify Sora's training data sources? It's the same lack of transparency.
➡️ Why not a mandatory information sheet, easily accessible from the product itself, with the training dataset's sources, compositions, possible biases, and so on?
➡️ We must overcome this phase of the "AI economy" and start enforcing stronger transparency obligations on AI companies. Regulators should take notice.
🔎 Google Search has changed
➡️ Last week, Google Search started hiding by default the number of search results. Here's why it's probably related to Google's AI strategy (and where you can still find this number):
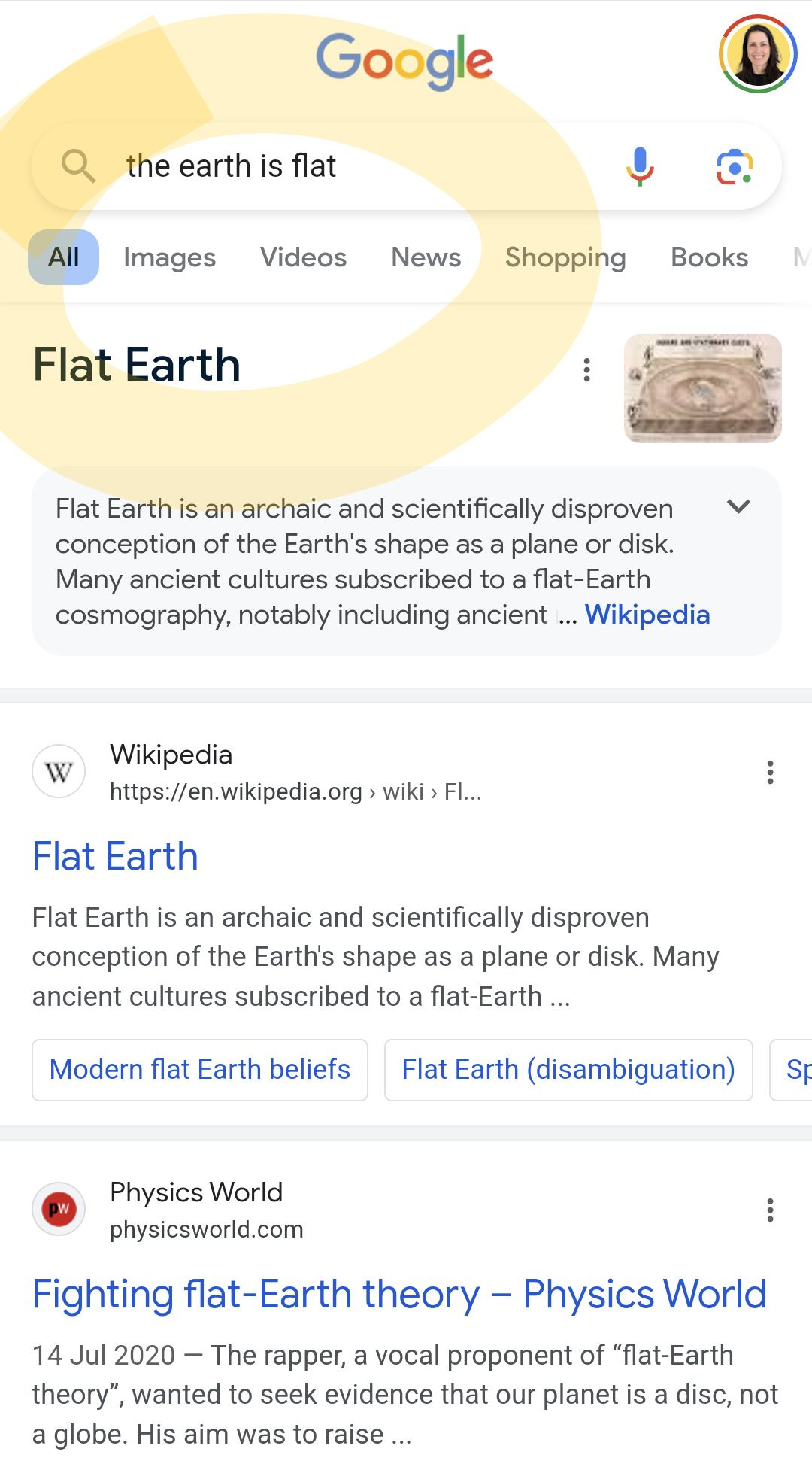
➡️ For those who forgot, the total number of results used to be displayed right under the search bar at the top of the search results.
➡️ Besides being an additional functionality to people in Marketing, SEO, and many other fields, it was also helpful to people who speak and write in languages other than their native one: you could quickly learn if a certain expression was popular or if it made sense at all in a certain language. I was surprised when I no longer saw the total number of results, as it was an exceptionally helpful tool.
➡️ My guess is that it was also helpful for people with various disabilities to understand more about how most people communicate or how most people perceive the world.
➡️ My view here is that they are preparing for further integrations between Generative AI and Search to compete with OpenAI, and showing the total number of results does not make sense when you will offer only one curated AI answer/output.
➡️ The Search vs. Generative AI integration becomes even more probable when it seems that OpenAI will very soon launch an AI Search product, and it's getting ready for that (see my previous posts).
➡️ The good part is that you can still find the total number of results on Google Search if you click "Tools" right under the search bar on the right side.
⚖️ AI copyright lawsuit: tentative ruling
➡️ The tentative ruling in the AI copyright lawsuit is favorable to artists Sarah Andersen, Karla Ortiz & Kelly McKernan, allowing discovery to proceed. An extremely important lawsuit that might change copyright law in the age of Generative AI. Quote:
"Beyond the Training Images theory (that suffices for direct infringement as to Stability, Runway, and Midjourney), plaintiffs have plausibly alleged facts to suggest compress copies, or effective compressed copies albeit stored as mathematical information, of their works are contained in the versions of Stable Diffusion identified. At this juncture, plaintiffs should be allowed to proceed with discovery. The facts regarding how the diffusion models operate, or are operated by the defendants, should be tested at summary judgment against various direct and induced infringement theories and precedent under the Copyright Act."
➡️ Read the tentative ruling here.
🎓 Master AI law

➵ As I discussed in today's newsletter, the ongoing AI disruption has brought numerous legal challenges and a regulatory boom, likely bigger than the one we observed when the commercial internet started.
➵ Legal and compliance professionals who fail to learn and master these new challenges, policies, and regulatory tools will miss a unique opportunity to stand out and advance their careers in this new paradigm.
➵ With that in mind, 700+ people have joined my training programs, designed and led by me to help you learn, upskill, and lead. We have two Bootcamps coming up in June. Check them out, read the testimonials, and save your spot:
➡️ The EU AI Act Bootcamp: 4 weeks, starting on June 6 - learn more and register here
➡️ Navigating Generative AI Legal Challenges: 4-week Bootcamp starting on June 3 - learn more and register here
➵ If you plan to attend both Bootcamps in June, you get a 10% discount on the second one. Write to me.
➵ Most people expense the Bootcamps out of their learning and development budget. If you need a customized invoice, let me know.
I hope to see you there!
🙏 Thank you for reading!
If you have comments on this week's edition, write to me, and I'll get back to you soon.
To receive the next editions in your email, subscribe here.
Have a great day.
Luiza